Hi I want to know the diameter of the red circle in the picture below

Hi @user-4bc389! This looks like a screenshot from our Reference Image Mapper video. It shows a reference image and a gaze circle on it.
Usually when people ask for the diameter of the gaze visualisation, they are interested in an answer in degrees of visual angle. Since this is "mapped gaze" on a reference object, rather than raw gaze in the scene video, this is however not possible. The angular error on the reference image would require additional information on how far the viewer was away from the contents of the image.
I could ask the team that produced the video what the exact radius was in pixels, but it's size does not really represent any physical value, so I am not sure that would be helpful.
hi! We have a recording that was successfully uploaded to pupil cloud but the world video does not play in the cloud or on the actual OnePlus6 device . We have locally exported the file, is there any supported way to get this local export back into pupil cloud so we can get enrichment processing on this file?
Does the local copy of scene video work?
actually - no it's not opening in quicktime
In this case, it looks like the file got corrupted during the recording. Could you please share the local copy of the recording with data@pupil-labs.com ? We can check if the video file is recoverable if you want.
thank you!
Hey everyone, I'm not sure if I missed something on the enrichment page or it just wasn't clear, but just have a quick question. Our study is designed to have a search task randomized via psychopy, each stimuli image is different. If we wanted to track the participants gaze for each slide, would we need a marker for each individual slide we wanted to track or can we just use set of 4 markers to outline the perimeter?
The latter is sufficient if you annotate the different slides via events (either manually or via the network API). Otherwise, if you use different markers on each slide, you can easily setup different AoIs without having to manually annotate events.
@papr Thanks for the help!
@papr i’ve connected the invisible with the one plus 8. for some reason, it just displays black screen. do i have to turn on some settings to be able to retrieve the real world rgb frames(scene video)?
when i tried to playback a recording, it says that the recording has got no scene video
Could you please specify where you see the black screen? In the app's preview? If yes, does it show the red gaze circle?
he’s in the app preview. i do see the red gaze circle
@papr Hey, so we decided to setup up markers on each stimuli slide. However, now we are facing error 400: surface location is not found (we recommend refreshing the browse).
When I refresh the page, the same error occurs.
Hi ,about the invisible data, when can I get the data such as fixation time and pupil diameter through the player? thank you
Hi @user-4bc389!
Fixation data will be available for Pupil Invisible in Pupil Cloud today!
Fixation data will be available for Pupil Invisible in Pupil Player in a couple weeks. The same algorithm used in Cloud will be deployed open-source in Player.
Pupil diameter will unfortunately never be available for Pupil Invisible in both Cloud and Player. The eye cameras of Pupil Invisible are so far off to the side that they often do not show an image of the pupil at all. Pupil diameter data is only available with Pupil Core.
Thanks
Can anyone verify a user named Dan who reached out to me directly resolve an issue?
Yes, I can likely verify that. Can you share their email via a direct message?
@user-2ecd13 that was me, I have DM'd you further questions for debugging
Yes, I already did and I'm waiting for a response
I am not sure if I am understanding you correctly. Dan reached out to you and you would like to know if he is a Pupil Labs member? I can verify this by having a look at the email address that was used to contact you. You did not share the address via a direct message with me, yet. Edit: We were able to verify the profile.
Official Pupil Labs members have a green name on this server. They own the pupil_labs_member role. You can check by right clicking the user name and hovering the Roles context menu entry.
@papr i see black preview with red gaze circle. i’m not able to see the actual rgb preview
Please contact info@pupil-labs.com in this regard
Hi - How do i connect my glasses to the pupil monitor app? It is just blank right now
The Companion device and the computer running the monitor app need to be connected to the same wifi. Also, the glasses need to be connected to the Companion device (and if necessary, OTG needs to be enabled)
If the glasses are recognized, a button to start the connection will appear in the ui
hmm the ui itself is just a blank screen to me
maybe i downloaded it wrong?
No, it is more likely that there is an issue with the network setup. Just to be sure, are you on a private network? public/University networks tend to block an important part of the communication necessary for the device discovery.
im on a public work network unfortunately
ok, you can share the pi_monitor.log file from the pi_monitor_settings folder and I can check if there might be anything else blocking the connection.
okay will send to you. also how do i read documentation on how to create a gaze mapping?
ive had pupil core but jsut today got pupil invisible (so trying to learn)
thanks for your help!
Pupil Invisible does not require a calibration. Checkout our documentation here https://docs.pupil-labs.com/invisible/
sorry i meant that i want to create a static image (that the gaze data is then overlayed on)
Check out the Enrichment section of the documentation 🙂
Hi @user-1e3de3 . If you want to map gaze to a static background try the Reference Image Mapper enrichment. Then you can generate aggregated heatmaps on a reference image: https://docs.pupil-labs.com/cloud/enrichments/#reference-image-mapper
i.e a static image of a freezer
yes exactly. thanks...i couldnt find this
I have a problem with an eye tracker (shown in the red area in the figure below). The OTG function of the mobile phone is also turned on, but it is always displayed in gray. What is the problem?

Please contact info@pupil-labs.com in this regard
Hello! how could i use the new fixation detection on existing recordings? thank you!
Hi @user-94f03a! This is not automatically possible through the UI, but we can manually start calculation of fixations for all your old recordings. If you DM me the email address of your Pupil Cloud account, I can facilitate that!
Thanks Marc, that's super helpful! will DM you
Thanks a lot for your feedback over in the 👁 core channel @user-e91538! ❤️ I'll paste it here for reference:
Personally I believe that this feature [defining and mapping to AOIs] will really make the difference. That's why people usually prefer tobii, but if you'll be able to bring this feature and increase its accuracy of the automatic mapping (because I understand that at this stage the accuracy is not really fine), you will get a lot of new clients, and I will be one of those clients as well! A suggestion that I can give you at this stage is to give the ability to the researcher to correct manually the automatic mapping in case the automatic mapping will be not correct. In addition, increasing the accuracy of the automatic mapping in order to use the automatic mapping also on dynamic and small stimuli (e.g. mobile devices while browsing a web site/ app) would make the difference. What do you think about it? thanks
I too believe that his is a key feature we are still missing and I am looking forward to having this hole filled. Let me give you a bit of an overview of our development roadmap. To me the most frequently required components for eye tracking studies belong mostly to 3 classes:
1) Eye-based datastreams: Gaze data, fixations and blinks.
2) Scene-based datastreams: Tracking various objects, faces, humans in order to correlate them with the eye-based data.
3) AOIs/Metrics/high-level analysis: The ability to define AOIs to distinguish data spatially. Further, the ability to easily distinguish data temporally or based on meta data (e.g. demographics). For each segment various metrics can be computed (dwell time, time to first fixation etc) in order to compare different conditions (trial A vs trial B, group A vs group B, etc)
Our plan is to implement features in roughly the order of those components, i.e. first features to generate relevant eye-based data, then features for analysing the scene video, and lastly
Face automatic detection is interesting but absolutely not a priority like having a working reference image tool. TODAY WHAT MAKES THE DIFFERENCE BETWEEN TWO EYE TRACKING COMPANY IS NOT THE HARDWARE, BUT THE SOFTWARE!!!!! That's a real truth. A software that speed up the analysis using the reference image, where after the automatic mapping you can fix manually some fixation, where you can draw AOI on, and export metrics (N of fixations, Eye Ball, TTFF, Dwell Time, Fixation duration, Revisits). Subgroup analysis is necessary for heat maps/ gaze opacity (mainly for visualizations), while for metrics export you can allow simply to download the entire dataset and than the user will be able to filter data in excel in his own (even though several filter will be useful in the future, filter related to the participants on each reference image, on metrics, on segments, etc...)
AOI/metrics features.
The reasoning is that from a technical point of view the difficulty is decreasing in this order. We would like to do as much of the heavy lifting as possible as quickly as possible and leave only the “easier” parts to the user to solve themselves.
Gaze data and fixations are already available in cloud and blinks will follow soon in Q1 2022. The Reference Image Mapper, Face Mapper and Marker Mapper enable several ways to analyse the scene video and to perform what is often called “gaze mapping”. We want to extend those features with the tracking of screens and mobile phones, as well as tracking of people in the scene and their individual body parts. Regarding the gaze mappers you said that “at this stage the accuracy is not really fine”. Could you let me know in what conditions you have tested them (or seen others test them)? I’d be curious to hear about the failure modes you observed. Generally I would say that the Face Mapper and Marker Mapper are both quite accurate and robust. The Marker Mapper comes with the obvious weakness that you need to have markers around your object of interest, which can be undesirable. In some lighting conditions the marker detection has problems, but this can usually be managed. The Reference Image Mapper has somewhat strict requirements on the environment, which needs to be sufficiently feature rich and static. If those requirements are met it is quite accurate, if they are not it does usually not yield results at all.
Did you have data with those mappers where you got noisy results where you would want to correct individual samples, or would you rather be looking for something to manually map an entire section of video sample-by-sample where a mapper failed?
I definitely hear your feedback regarding the need for AOI-based analysis. We have received this feedback multiple times already and will definitely address it within 2022 (hopefully the first half!).
@here I would also be interested in hearing from everybody else! What feature are you missing the most? What were your experiences with the existing gaze mapping tools? I’d be super happy to hear what other troubles you have and to adapt our development roadmap to address high-priority features we can identify!
I have a couple of questions about the data files. If I download the files from the cloud and plot gaze together with the images myself, I get a slightly different gaze pattern than if I look in pupil player. It is quite a small difference, so my guess is that I am interpreting something slightly wrongly. My guess is that I have the timing wrong, because the times of the first and last image do not match precisely. I assign each frame to the time in ‘world.time’. Is this correct, or should I be assuming that the frame rate is constant? Maybe that is the difference because the total duration seems to match but the temporal offset does not look constant (though it is hard to tell). Moreover, I subtract the starting time from ‘info.invisible.json’ from each time of the frame, but this seems to give an offset relative to the times in pupil player. Such an offset is obviously no problem, but if I need to shift the times in the scene video relative to the times of gaze (where I use ‘gaze ps1.time’, ‘gaze_200hz.time’ or the time column in ‘gaze.pldata’ to determine when the data were acquired) the reason for the discrepancy would be clear and my interpretation would be wrong. It appears that there might be more times in the time file than images in the video from the scene camera, so maybe that is where my timing is off. I am assuming that the problem is in the timing, because I guess the scene image deformations do not need to be accounted for because they are part of the ‘training’ of the network. I just scale the gaze values linearly to match the image. Should I be doing something more complicated?
Thank you @marc it sounds a great plan! Regarding the accuracy I did not test it, I just trusted your documentation about the "The Reference Image Mapper", that stated that:
"Mobile phone or tablet screens. Not suitable due to dynamic movement within the environment and dynamic content displayed on screen."
I also heard from some collegues using invisible + imotion software for reference image analysis that there is some issue in the accuracy of gaze recording in case of digital stimuli (mobile website, app) that are generally small. If you are agree, I would encourage you to think about some workaround to increase accuracy in general, for example adding some method in the analysis software that allows to manually fix the gaze position in some case.
IMPORTANT: In tobii pro lab, while dealing with the reference image mapping, you can manually fix the position of the gaze when you see that it is not correct. It is easy to do, because you have two windows: the left one show you the environment and the position of the gaze, while the right window show you the reference image and the position of the gaze on such image as the result of the automatic mapping. While the outomatic mapping is terminated you are able to move on the timeline and quickly check if the result of the automatic mapping is correct or no, simply visually comparing the 2 windows views. When you see some discrepancy, you can simply correct the fixation on the reference image, clicking in the position where the fixation should be. That's great.
Personally I don't like the "markers" approach, it could be fine 10 years ago, now the real challenge is to build an effective reference image tool.
I have always wondered regarding these manual correction tools: Aren't you manipulating your study results if you apply them? How do you handle using them as a researcher? Edit: I need to clarify. In case of the reference image mapper, you have the scene camera gaze as "ground truth". My question was meant generally, e.g. for manual offset correction tools, etc.
Thanks for the further clarification. It is correct that the Reference Image Mapper does not work for mobile phones and tablet screens. Those screens do both move in space and share their appearance when the display contents change.
We have successfully tested the Reference Image Mapper with stationary computer screens though, and with mobile but static objects like magazines.
I have never tried the iMotions gaze mapping myself and can't judge it's quality. I have seen the manual mapping tool in tobii pro lab. While we are not currently working on a method for correcting a gaze mapper, we will introduce a similar visualisation of mapping results in our upcoming release for Pupil Cloud. You will be able to see the scene video next to the reference image and see mapped gaze on the reference image during playback.
No, because you see that it is a clear error of the algorithms for the object recognition. In addition you see in the left window exactly where the fixation should be located, so you simply move the fixation in the right place
Yeah, agreed that in this case, manual correction of object-mapped gaze is valid.
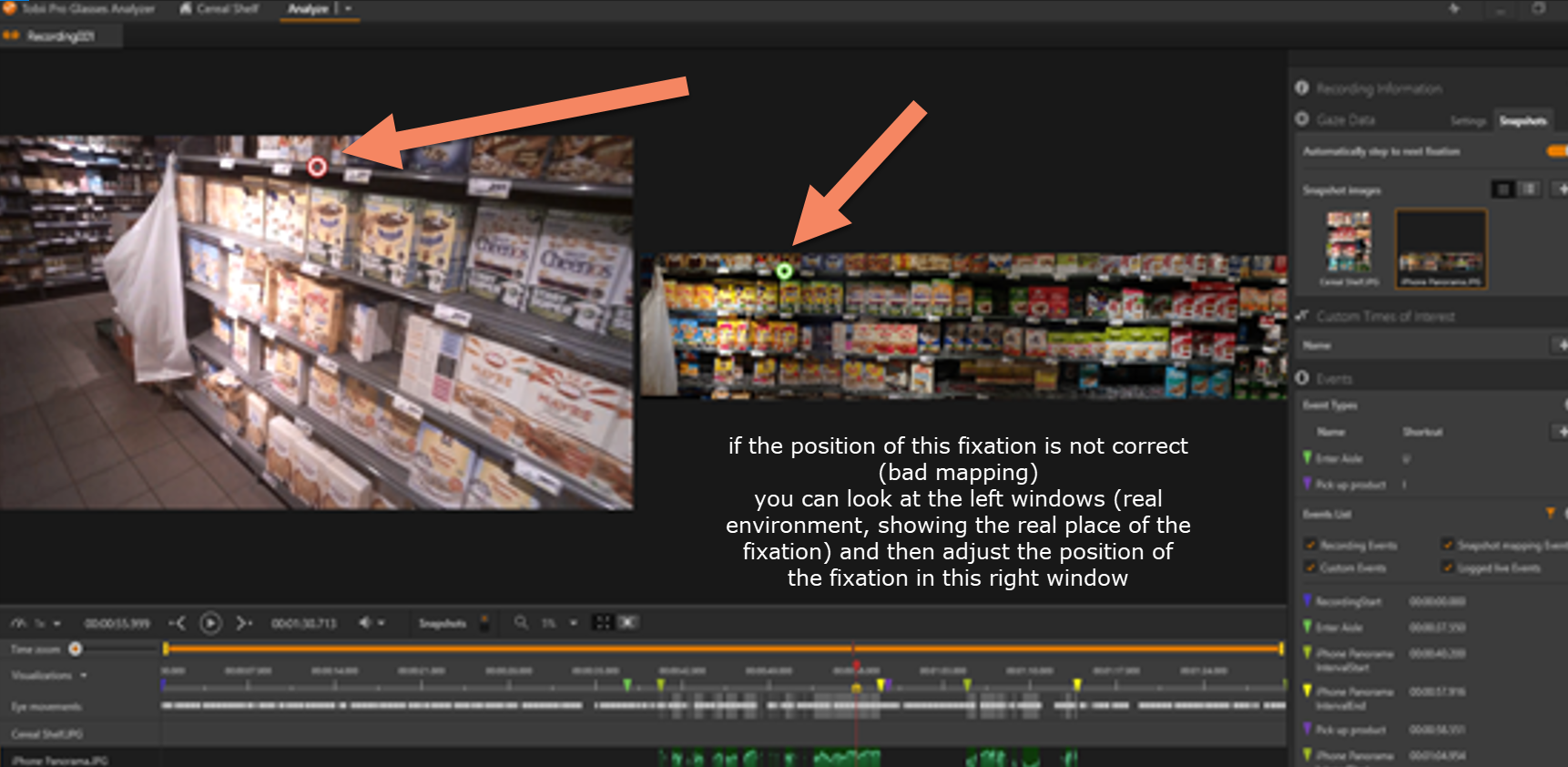
Thanks, that makes it clear! Exactly this type of visualisation (except for the ability to make the corrections) will become available in our next release in January.
Gaze in Player vs Cloud
Yes, I believe that it is already a great feature. Said that, for the next future I think that manual correction and compatibily with the analysis of mobile app will be crucial. Both aspects are crucial for example in my case, that's why I use Tobii pro lab. I think that Tobii hardware and software are too expensive, and I really would like to move to other hardware/software like your, but the truth is that at the moment they allow some features like those that are crucial to researchers and they only provide. Said that, I will get updated, because I think that your solution, after the reference image mapper will be integrated with AOI and metrics features, will be extremely interesting for the analysis in point of sales. But please, consider that now most of the research is digital, and if you will allow to run analysis on digital stimuli, the eye tracking market will become only your 😉
Thanks for the feedback, it is much appreciated! We will definitely consider it in our prioritisation. In scenarios where the screen is stationary, the Reference Image mapper should work already and we will definitely look into tracking mobile screens as well. AOIs are for sure on the roadmap as well as mentioned! We'll be working with full force on all of those in the next year! 💪
Hi...it seems the spot is not exactly centered with gaze. what can I do?


Those two images are showing interaction at a fairly close distance <1 meter away. When gazing at things this close to the subject, the gaze estimation is suffering from a "parallax error", which is essentially a bias in the predictions.
We can see that in both images there is a similar offset to the left. Before starting a recording you can use the offset correction feature in order to specify and compensate this offset. This will however lead to an inverted when gazing at something that is >1 meter away.
should I use different offset corrections depending wether the operatore looks at things at close distance or at long distance (>1m)?
That would be ideal, however you can only set one value per recording. If the operator is switching between close and far within the same recording, it is unfortunately not possible to get entirely offset-free predictions.
ok..Thanks a lot, Marc
So, if I set more than one meter distance, and then I record a tennis play, invisible will not give me the right data for all of this (far/near) ball movements?
For distances >1 meter there is no noticeable parallax error, but for distances <1 meter there is. You can use the offset correction in order to compensate for this error at close distances, but this will in turn create an error for further distances.
During tennis I imagine the gaze target is predominantly further away than 1 meter, so most of the time there should be no parallax error. If you are e.g. specifically interested in the player gazing at the ball just before hitting it and while it is very close to him, this section may be affected by parallax error and could be improved using the offset correction
Hi Does invisible have to be connected to one plus 6 or one plus 8? thanks
Yes. OnePlus 8T is also supported.
OK thanks
Could you please verify the latest supported version of Android for the Companion app?
Hi @user-e3c1d6 👋. The Companion App is compatible with Android 8/9 on OnePlus 6, and Android 11 on OnePlus 8/8T