Hi, I'm doing a gaze controlled mouse for multi-monitor setups using Pupil Core for my thesis and wanted to ask if one needs to calibrate pupil core through pupil capture's calibration (5 point) if April tags and surface tracking are being used please? Thanks (I'm using the pupil helper "mouse_control" but trying to extend it for multiple surfaces representing multiple screens in the real world)
Hey @user-e440bd, there are 2 things being tracked here, 1.) the screen, and 2.) the gaze. The April Tags are used to track where the surface is, whenever the tags are visible in the scene camera. However, this doesn't give you the gaze, which is where the eyes are looking.
Calibration is required to track gaze, since this is how you associate the eye images with known coordinates in the physical environment.
In short, you need the April Tags to track where the screen is, and you need to calibrate to track where the gaze is.
In a multi-monitor setup is there a way to save calibration settings and resolutions of multiple monitors in separate files (rather than one calibration setting overwriting the setting of the previously calibrated monitor) and keeping in mind each monitor has a different apriltag, when the user is looking at a certain apriltag for a few seconds, it loads and refers to the settings of that specific monitor and the mouse is shifted to that monitor and vice versa for the other monitor with a different apriltag, please? Thanks and greatly appreciated.
Hi, @user-e440bd - I might jump in here for a second. First, pymouse has been stale for over 10 years - it was merged into pyuserinput, which was deprecated for pynput. Personally, I prefer pyautogui, but if pynput does what you need I doubt any other differences would matter much.
It's important to understand that when you perform a calibration, you're not calibrating anything to do with the screen - even if you're using the screen marker calibration choreography. Rather, calibration is about defining the relationship between the pupil core cameras and your eyes. The screen marker choreography is just one way of collecting data across a range of eye positions - the screen itself is just a medium for displaying target markers in different places so that you have to move your eyes for varied calibration data points.
So, to do gaze-based mouse control across multiple monitors, you'll need to define a separate surface (with distinct markers) on each display. Your code will need to identify which screen is being gazed upon (by examining the surface name), and then move the cursor to the surface gaze position offset by that monitor's virtual position. Pupil Core doesn't know that the surfaces you have configured are monitors, nor does it know about your monitor layout. You will need to handle this logic in your code.
For example, if you have two 1920x1080 monitors side-by-side, and you detect at a gaze at (100, 100) on the second monitor, you would need to move the cursor to (100 + 1920, 100)
Ah ok thank you very much, it was very helpful 🙂 Will try doing this and will keep you updated 🙂 what i noticed about pymouse is that, it doesn't handle monitors at all whilst pyautogui does. Havent used pynput yet to be honest. Which pupil helpers might be best for me to see? The "filter_surfaces" and mouse_control" ones or do you recommend any others? Thanks. Up till now I've managed to define 2 surfaces with 2 separate apriltags from the 36h11 tag family
Also how can one save multiple pupil core calibrations for multiple monitors please? Cause currently im facing a problem where the calibration of the second monitor is overwriting the calibration of the first monitor. Thank you very much very appreciated 🙂 and sorry for bombarding you guys with questions
That's ok - there are some important fundamental concepts to understand here, so it's good to make sure the understanding is clear 🙂
When you perform a calibration with Pupil Core, you are not calibrating anything to do with the monitors - even though the monitors are involved if you use the screen choreography. What you are calibrating is the relationship between the cameras and the wearer's eyes.
This calibration gives us a gaze point from the perspective of the scene camera. It still has nothing to do with the monitors, and nothing about the monitors is saved with the calibration.
But since we put AprilTag markers on the monitors, we can calculate the relationship between the monitors and the scene camera. So now we know the gaze point relative to the scene camera (which comes from calibration) and the display surface relative to the scene camera (which comes from the AprilTags).
Thank you very much for this. For the eye tracker to run and "see" the pupil helper's code of for example the filter_surfaces helper i just need to paste the Python file in the plugins folder, right? Thanks.
I'm not exactly sure what you're referring to, but what you probably want to do is write your own python program that communicates with Pupil Core over the network API.
The Pupil Helpers repo has an example Python app named mouse_control.py that does exactly this. It is not a Pupil Core plugin. Rather, it's a separate program that receives gaze data from Pupil Core
And how do i run it to make sure its communicating with pupil core? From the IDE (pycharm or vs) is enough or i need to place it in a specific directory? I was going to modify the filter surfaces program, since i have multiple surfaces too in my case
Hi @user-e440bd ! One clarification, as long as you have the Network API plugin enabled in Pupil Capture and Pupil Capture is running, the data can be streamed and access through your network on your computer from a different program.
On the example that my colleague shared, you can find the address and port being specified at the beginning.
addr = "127.0.0.1" # remote ip or localhost
req_port = "50020" # same as in the pupil remote gui
Here set to locally on your computer, although you can use a different computer through your local network using the IP of that computer.
BTW, If you think it would be beneficial for you, please consider our custom training and consultancy packages, which include code reviews and step-by-step guidance.
Thank you for this, so as long as I use that address and request port, I should be fine 🙂 Will definitely consider the training packages. Very appreciated.
Hi, I have a question about pl-neon-recording. I am trying to grab the scene at the time of the user input. The user input triggers a custom event, (time-adjusted for companion device, per documentation) sent out via real-time API. Following the usual examples from the sample code for reading the exported recording, if I do the following:
evt_timestamps = recording.events.ts
scane_sampled = recording.scene.sample(evt_timestamps)
events_sampled = recording.events.sample(evt_timestamps)
combined_data = zip(
evt_timestamps,
events_sampled,
scane_sampled,
)
I notice that sometimes, the scene sampled has timestamp "after" the event, and the scene has changed by then. I understand the ... sample(...) function for the streams have an interpolation option, however it defaults to 'nearest' without offering further customization. I feel there should be some option for nearest timestamp in the other streams that is less-than or equal to (but not exceeding) the event timestamp.
Are there more interpolation types, or should the users roll their own for cases like this -- Kindly advise.
Hi, so i've managed to run the "filter_gaze_on_surface" pupil helper successfully with the guidance of your colleagues, however if i look at monitor 1 with monitor 2's apriltag or if i look at monitor 1 with monitor 1's apriltag (the right apriltag associated with the monitor this time round), it still displays screen 1 in the terminal (screenshots for reference). When i look at monitor 2 only with monitor 2's apriltag, it still displays that im looking at screen 1 too. It's like any apriltag it sees is screen 1 even if it is associated with screen 2 via pupil capture's surface tracking plugin. What am i doing wrong pls? Thanks. For context screen 2 is the one on the left (the monitor) and screen 1 is the one on the right (the laptop's screen). (opened a thread to not explode main chat with images)
There are only the 2 interpolation options so far, but I like your suggestion. Do you mind making a post in 💡 features-requests?
Done. Thank you.
Hi team! I want to display the tracking of fixation points in the scene camera, similar to what we see in videos on Pupil Cloud. I already understand how to analyze fixation coordinates relative to the video in the scene camera (https://github.com/pupil-labs/pl-rec-export.git). But, I am asking specifically about tracking fixation surface points in the real world and how to obtain them as coordinates in the scene camera. If there are any scripts available in this community, please let me know🙏 🙏 . (I have already checked https://github.com/pupil-labs/pupil-community?tab=readme-ov-file#real-time-network-api-clients.) thank you!
Hi @user-43ec86 , to be sure I understand, is part of your question asking how to find the point that is gazed/fixated in 3D coordinates (i.e., the location in the world that is being looked at)?
Or do you want to know when someone is looking at say a book or a cup in the scene camera image?
Feel free to draw an example if that helps.
Hi, @user-f43a29 Thank you for response! If say simply, I am asking how to get fixation 2D coordinates consist of movie in pupil cloud like this. But, it’s important that each fixation points moves continuously in response to head movements.
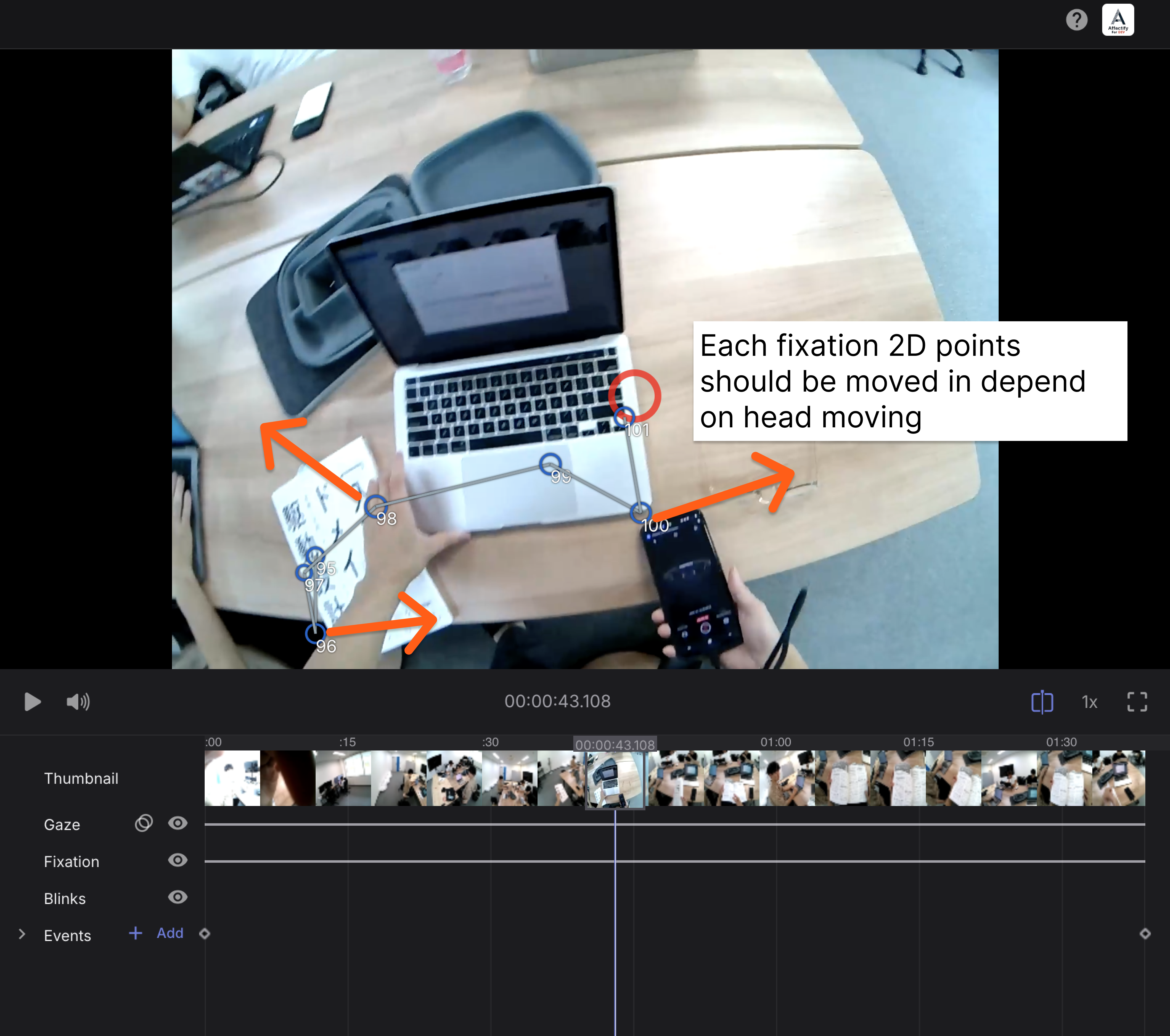
Sorry for my bad English...
Hi Rob, I haven't used the pass-through feature, so I'm not sure how it could affect the issue with the background during calibration. It seems like my problem might be related to something else.
Hi @user-224f5a , then I think I misunderstood. Do you mean:
Hi @user-43ec86 , no worries. I just wanted to be sure that I point you in the right direction.
Here are two options:
/workspaces/{workspace_id}/recordings/{recording_id}/scanpath.{format}?start={start}&end={end}&max_length={max_length}, where {format} can be .json, for example.Here is an example of how to work with the Pupil Cloud API in Python, as provided by my colleague @user-d407c1 .
Please note that there will soon be a minor update to the data provided by the scanpath 'endpoint' of the Pupil Cloud API, so you may want to wait for that update.
Thank you very much!!!! this is what i looking for
I got detect_fixations in pupil_src/shared_modules/fixation_detector.py's Intention !!
To use this code it will load fixation.csv and export new optic_flow_vectors.npz account for optic flow right?
And, Piuil Cloud API also effective solution for me!! I will try both two options!!! Thank you 🙏
Glad to hear that it will be of help!
To clarify, Neon Player does not export new optic flow vectors, but rather uses the cached optic flow vectors, as computed by the fixation detector in pl_rec_export. You can check the code of _process_fixations for more details.
Do note that re-purposing the code of Neon Player does require significantly more coding effort, so if you are not under time pressure, it might be easier to test the Pupil Cloud API approach first and use that once the update is released.
Thank you for advice!!! I tried to use Pupil Cloud API approach and got solution!!! Really appriciate the team!!
I am trying to pip install pupil-master but ndsi and pupil-detectors are failing to install on Ubuntu 22. All the other packages in requirements.txt installed well. Is there something missing to install ndsi and pupil-detectors on Ubuntu?
Hi @user-f7a2f7 👋 !
develop branch and working with that, rather than using the master branch?Thanks Rob! The .deb installation worked well for Ubuntu!
Hello everybody! I would like to generate a Scanpath Visualisation with Google Colab and followed the instructions on this page: https://docs.pupil-labs.com/alpha-lab/scanpath-rim/#generate-static-and-dynamic-scanpaths. I recorded eye-tracking with Pupil Invisible and created a new video file in the Pupil Cloud with the Enrichment Type Reference Image Mapper. It is possible to download the Enrichment as CSV files. The Google Colab notebook needs that for generating the Scanpath Visualisation. Unfortunately in my case, the downloaded Enrichment CSV files of the Reference Image Mapper do not consist of any data that could be processed by Google Colab. But there is also no error message, not in the Pupil Cloud and not in Google Colab. I noticed because there was no Scanpath video generated by Google Colab and then checked the CSV files. The Google Colab notebook I used was: https://colab.research.google.com/drive/13FIZroc7ckyOs7APSSskqo7ew2JAZR-q?usp=sharing. It was possible to generate a Scanpath video file with data from the Enrichment type Manual Mapper and with the same Google Colab notebook, but the video file couldn't be opened with a regular video player. I would be glad if you could help me with this and thank you for answering my request in advance.
Hi @user-52a823 ! It sounds like all the cells are executing without errors, but you’re not seeing the video output. Could you try running the Colab using a Cloud API token to rule out any issues with the download? Also what files are there in your download?
It would also be helpful if you could create a copy of the Colab, run it with private outputs enabled, and then share it with us so we can check the output cells.
Hello @user-d407c1 ! I tried with the Cloud API token, but there was also no Scanpath video file in the output, only the reference image. In my download are the following files: sections.csv, gaze.csv, fixations.csv, aoi_metrics.csv, aoi_fixations.csv, reference image, enrichment_info.txt.
Could you please tell me in which section you need the Colab code of the output?
I assume there are instances of gaze over the reference image on the Cloud for that specific recording? Could you share the fixations.csv file and the recording ID?
Yes, the gaze overlays the reference image, when I understand you right. I send you the fixation.csv file and the recording ID as direct message.
Hej PL team. Is Eye State Data available in the raw recording loaded from a Companion App? If it is available could you please point me the raw eye state data format documentation or code. Thank you.
Hi @user-912183 ! Yes, eye state data would be available in the raw recording format, if you had the eye state toggle enabled in the settings.
To read the Neon native format data, I would recommend that you use pl-neon-recording library, which would read all the files for you and have examples of using that stream, but if you want to read yourself, that library also shows how https://github.com/pupil-labs/pl-neon-recording/blob/main/src/pupil_labs/neon_recording/stream/eye_state_stream.py
@user-d407c1 Thank you for detailed info!
Hello Pupil Labs team, could you please tell me, which code blocks I have to change in Google Colab to adjust the color and line thickness of the points for the Scanpath video?
Hi @user-52a823! The scanpath color is generated randomly in this snippet:
random.seed(42) num_unique_colors = len(unique_wearer_names) random_colors = [plt.cm.viridis(random.random()) for _ in range(num_unique_colors)]
A unique color is then defined for each wearer:
color = random_colors[idx]
and the following line plots the fixation circles:
ax.plot(x_rescaled, y_rescaled, 'o', markersize=marker_size, markerfacecolor=color, markeredgecolor='black', alpha=0.5)
If you want to change the color, you can simply replace the markerfacecolor=color with a color of your choice, e.g., markerfacecolor='red'
By "thickness of the points" do you mean the size of the circles? This can be adjusted in the Select your scanpath parameters by changing the numbers for minimum_size_fixation_circle and maximum_size_fixation_circle.
To change the thickness of the lines connecting fixations, you can simply modify the linewidth number in the following line:
ax.plot([prev_x, x_rescaled], [prev_y, y_rescaled], 'black', linewidth=0.5)
Thanks, @user-480f4c !
Hello! I have recording files from a Unity experience using Vive + eye-tracker add-on, captured with Pupil Capture. I've exported the data into CSV files, which includes a fixations file.
Is it possible to use this data to recreate the fixations points in the Unity scene?
The gaze_point(x,y,z) doesn't match up. I've tried recreating what the GazeVisualizer script (provided on the Unity package) does for this but it's not working as expected either.
Hi @user-13d491 , what is your comparison when you evaluate the data in the fixations.csv file?
Is it possible to provide an image of what you mean by "the gaze_point doesn't match up"?
Hi Rob, what I did specifically: I selected a fixation from the list and checked in the Pupil Player what is the target of that fixation (a vase inside the room) which you can see in the first picture. Using the gaze_point_3d values (x,y,z) associated to this fixation in the CSV file, I'm trying to visualize this fixation in the same Unity scene. From the XRCamera, I'm drawing a ray towards the coordinates from gaze_point_3d, but the resulting ray (in red) is pointing at a very different direction (second picture).

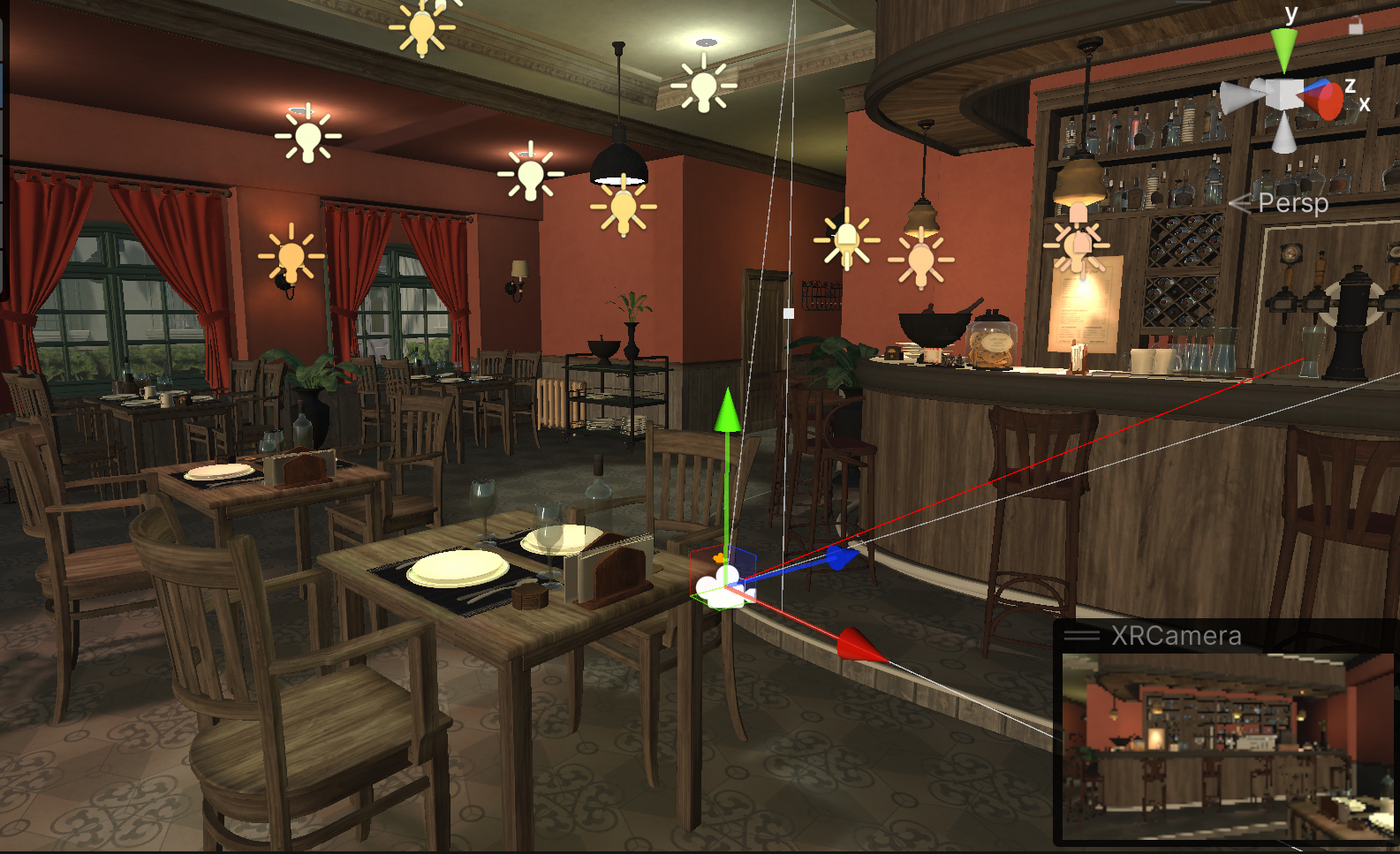
May I first ask if you've also accounted for the head rotation (i.e., the rotation of the xrCamera)? It looks like the XRCamera is turned to the right and looking at the barstools, whereas the observer had their head turned to the left of that.
In terms of code, I'm doing something similar to the GazeVisualizer.cs script, the ShowProjected method, as following:

May I first ask if you've also accounted
Hi team, I’m using the realtime_api and tested the Scene Camera Video with Overlayed Gaze in the Asynchronous Examples. I added logging before and after the cv2.imshow line, but I noticed it took about 4 seconds to get the first gaze point. Additionally, no image was displayed, and the log after imshow never ran.
I’m running this on Ubuntu 22.04 with Python 3.11.7, and Neon.
Also, could you let me know what the expected frequency is for receiving gaze data and frames when using the asynchronous APIs?
Thanks!
It's normal for the first image in the stream to take a few seconds. The issue you're having with cv2.imshow though is a bug that comes from an incompatibility between the version of ffmpeg compiled with pyav versus opencv. I know of 2 work-arounds. You can try removing and reinstalling pyav from source: pip uninstall av && pip install av --no-binary av
Sometimes though (at least on my system), pyav fails to build. I do not recommend going down that rabbit hole. Instead, an alternative workaround is to import opencv first, call imshow to create a window, and then call destroy all windows. After all that, then import pyav and everything works as expected
Thank you for the information! The later solution works perfectly fine for me!
Good morning, We started using the Neon's with the cloud platform, and so far love it quite a bit. But one thing we are looking into right now is wider CV support, running custom models for object detections. Our idea was to download the native data, and run a model such as YOLO in a separate environment to compare this to the available Gaze Data.
Are there already tools for this that can use the Pupil Labs data, and is a separate environment the best solution or is there an option to build this within the existing enrichtments?
Hi @user-0d28eb 👋 Thanks for your question. Glad to hear you're enjoying Cloud! I definitely see the benefits of running different CV algorithms on eye-tracking recordings. We don't have a way to do exactly what you suggest, that is, to 'customise' an enrichment by adding/running different algorithms in Cloud. That said, you can download data from Cloud programmatically using the Cloud API and subsequently run algorithms locally. A follow-up question would be, would you then want to pipe the results back into Cloud in some way, ready for computation of metrics?
Hey Neil, Thank you for the response. I expected that to be the case, wanted to be sure about it though. Custom CV algorithems can be quite intensive on your infrastructure, so i see why you wouldnt support that at the moment.
We did not yet consider piping the result back into cloud at this moment, but thats a very interesting suggestion. Our initial attempt would be largely manual. The research group is accustomed to retrieving data and running it locally, so maintaining that approach is key to get the functionality quickly integrated with their current projects and workflow.
Hi @user-0d28eb 👋 ! Please allow me to step in for Neil and refer you to this message https://discord.com/channels/285728493612957698/446977689690177536/1260964755984744609 where the different endpoints in Cloud are provided.
You would need to generate a developer token in Cloud, and then use it simmilarly to how its done in this gist, this way you would be able to fetch frames and gaze or fixation points and utilise them with your algorithms.
I also have another question: I’ve been testing the eye tracker using the Python API, specifically recording and receiving data in real time. I noticed a difference in the number of gaze points I get between recording and real-time data collection. For the same time frame, I receive around 2,000 data points when recording, but only about 400 points in real time. Additionally, the number of data points decreases even further when marker mapping for surface tracking is done using Real-time Screen Gaze.
Could this be related to internet latency, or is there another reason for this discrepancy? Also, are there any solutions or suggestions to improve the real-time data point collection?
Thanks in advance for your help!
In order to maintain the real-time-iness of the real-time API, some data will be dropped/skipped/missed if the network is slow or the consumer is not fast enough. One way to test whether it's your network or your processing code is to write a very simple consumer that does nothing with the data than to note that it has received a frame. If this receives as many samples as your real code, then you know the network is the likely bottleneck, but if the simple consumer sees more frames, then your real code is the likely bottleneck.
In my experience, it can help to separate tasks so that they can be run in parallel - like separating the the receiving of the data from the processing of it. Mapping to a surface like with the real-time screen gaze package, for example, requires some computation for detecting the the tags, calculating the position/orientation of the surface, and then projecting the gaze onto that surface - and this certainly does add up. Note also that, if I remember correctly, the real-time screen gaze examples use the get_matched_scene_and_gaze function, which will only return samples at the scene camera's frame rate in the best-case scenario. You can alternatively retrieve scene frames (at ~30 Hz max) and gaze data (at ~200 Hz max) separately, and then perform your own matching before sending it off to the screen-gaze-mapper.
Hej PL team. I am trying to get a live stream from the Neon companion using the samples (for ex. from https://pupil-labs-realtime-api.readthedocs.io/en/stable/examples/async.html). I can connect the device directly (device = Device(address='192.168.2.159', port=8080)), I can retrieve the device status (status.direct_gaze_sensor()), I can start/stop recording, but when I try to get the gaze data (either async or sync), I get no gaze data and infinite "no RTP received for 10 seconds: closing" output. I can see the live data in the browser (neon.local:8080). The device discovery does not give any devices as well, btw. I tried to run the PL samples code on 3 different local networks with the same result. Do you have any ideas what might be the problem in this case? Thank you.
Hi @user-912183 ! Could you share which version of the Companion app and Real-Time API you’re running? Also, is this in a virtual environment, and what Python version are you using?
Companion app version 2.8.25-prod, pupil_labs_realtime_api 1.3.3
from pupil_labs.realtime_api.simple import Device, discover_one_device
def main(): device = Device(address='192.168.2.159', port=8080, start_streaming_by_default=True) calibration = device.get_calibration() # this is OK print(calibration) a = device.receive_gaze_datum() # No data, "Error on stream: RTSPConnectionError('Unable to connect to 192.168.2.159:8086'). Reconnecting..." print(a) # never printed
@user-912183 I moved this conversation to 💻 software-dev as it might be more appropriate.
May I ask what OS and from where are you running the script (terminal, vscode,...) ?
actually I am running on Ubuntu in WSL: DISTRIB_ID=Ubuntu DISTRIB_RELEASE=22.04 DISTRIB_CODENAME=jammy DISTRIB_DESCRIPTION="Ubuntu 22.04.4 LTS"
Microsoft Windows 11 Pro, version 10.0.22621 build 22621. I am running in vscode version 1.93.0
Could you try it directly, executing it on Windows? And double-checking that Windows firewall or any other firewall you may have is not blocking the port 8086 for non web browsers?
Yes, I managed to run in on pure Windows and I can get the gaze data, it seems the problem is in the 8086 port forwarding
Could you give me a clue where what Windows firewall options I have to check.
First, I suggest running it directly on Windows instead of through WSL. If it works, the issue is likely related to how the WSL ports are configured.
Please note that we cannot assist with configuring Windows port forwarding to your WSL virtual machine, and this forum isn’t the best place for that type of support.
If you continue using WSL, you might need to forward the ports to access them outside your host machine. For guidance, I recommend checking out netstat interface portproxy
thank you, I'll try that. Are there any other ports the realtime api uses besides 8080 and 8086?
You can find more information about the protocols employed here, and as to which ports they can change as they are allocated based on the available ones in the device, so for example, if 8080 is in use because you are streaming something else, like the screen of the phone, then the default port will shift to 8081.
got it, thank you so much for you help!
Hi guys, I have some recordings done on Neon, some on Invisible. Now i want to compare heatmaps but the video frame size of Neon is much biger then Invisibles, right? Is there a way i can appropriately compare them statistically?
Hi @user-5ab4f5 , is it necessary that you run one Enrichment for only Neon recordings and another for only Pupil Invisible recordings? May I ask what exactly you are trying to compare with the two different heatmaps?
@user-f43a29 In short we had 3 conditions (2 different experiments), however during the 2nd experiment we changed to the Neon because we had issues with the invisible. I mean, can i still do an enrichment or a compuation via Python of the heatmaps for both types of data? (theoretically i wouldnt need to compare neon vs invisible but expierment 1 vs experiment 2), however i am not sure if this is appropriate considering the frame sizes to "merge" them together when we used different methods (which is the eye tracker esentially)
Hi @user-5ab4f5 , have you tried loading the Pupil Invisible and Neon recordings into one Reference Image Mapper Enrichment and running a subsequent Visualization?
If you need to run separate Enrichments & Visualizations, then with Reference Image Mapper, you will be comparing heatmaps for the different Reference Images that you upload, so the different scene cameras of Pupil Invisible and Neon should theoretically not play a role.
Otherwise, the details of the Heatmap implementation are in the documentation (at the bottom). You can then run your own visualization code on the Enriched Data, if desired.
Hi all, i was trying to use the IMU data visualizer (https://github.com/pupil-labs/plimu) to get a feel for the data. After cloning the repository and following the install instructions (no errors or warnings), i'm able to run plimu_viz, but no visualizer window pops up. I've tried to start the program with and without the video preview window on, as well as with and without a recording on. I have also started the video preview video and a recording after starting the program. I believe the program is able to communicate with the Companion App on the Companion Device because when i exit the app (with the program still running), the console gets filled up with RTSP Connection errors ("Error on Stream: RTSPConnectionError('Unable to connect to 10.42.0.236:8086). Reconnecting.... I'm running this on an Ubuntu 22.04 machine with Python 3.10.12. The phone, glasses and computer are connected via an Anker Hub. In case the Companion App settings are useful, i've got lab streaming layer disabled, my workspace will not upload egocentric video to the cloud, but will upload all else. Install was not done as sudo. If anyone has advice on troubleshooting, or pointers, i'd appreciate it.
Hi @user-97c46e , may I ask if 10.42.0.236 is still the IP address shown in the streaming section of the Companion App? The Unable to connect error message suggests that either the network connection has been disturbed or the IP address of the device has changed, potentially after a reboot.
I assume you have version 2.8.25-prod of the Neon Companion App installed?
Also, you do not need to install or run plimu as sudo.
@user-97c46e, I've moved your message to the relevant channel 🙂
Thank you. Apologies for the cross-post. Still very new to discord 🙂
@user-f43a29 , the sequence of events was that i ran plimu and had niether a UI or any console output giving any kind of status update for whether things were running or not. After a few times of starting and restarting everything from scratch, i tried to check whether plimu was even communicating with the device by killing the Neon App (just to inject failure, to see if i get any kind of info useful for troubleshooting). It is only then that is saw the Unable to connect sign (when i broke it myself - which told me it was probably communicating fine - it just did not provide any console output to tell me that comms were ok). Yes we have 2.8.25-prod on the phone.