Hello, I frequently get an "Internal Server Error" message when I try to delete trashed items in Pupil Cloud. So I cannot delete them. As a desperate measure, I am dealing with this problem by deleting the entire workspace. For privacy reasons, I would like to delete items that are no longer needed completely, but is there any way to solve this problem?
Hi @user-52e548! It's definitely possible to delete trashed recordings in Cloud. I'm unable to replicate the issue you describe, however.
Could you please try doing a hard refresh of your browser window and then looking in your trashed folder? I feel like the browser window may have been caching the page - i.e. recordings were already deleted when you tried to delete them.
If that's not the case and it turns out your recordings are still there, please send an email to info@pupil-labs.com with an ID of one of the recordings. To get the ID, right-click on a recording and select 'View recording information'
Thanks for your reply! I have sent an email to INFO, please check it out.
Hi @nmt I'm referring to neon, but would also like to understand core's respective numbers. Thanks
For Neon, we are soon to release a whitepaper that will outline this in more detail. I don't have a concrete date, unfortunately, but keep an eye on the announce channel 🙂. For Core, recommend heading to this section of our blog which talks about this in more detail.
Greetings, I'm trying to trigger a calibration sequence from a Python script while Pupil Service is running. After setting pupil_remote as a socket from a ZMQ context object, I run:
pupil_remote.send_string('C')
print(pupil_remote.recv_string())
However, this causes Pupil Service to crash with the following log output:
2024-03-06 11:47:46,732 - service - [ERROR] launchables.service: Process Service crashed with trace:
Traceback (most recent call last):
File "launchables\service.py", line 287, in service
File "calibration_choreography\hmd_plugin.py", line 81, in on_notify
File "calibration_choreography\hmd_plugin.py", line 126, in _prepare_perform_start_from_notification
KeyError: 'translation_eye0'
Am I doing something incorrect here? Do I need to first specify a calibration choreography? Any assistance here is appreciated.
Hi, @user-069d41 - Pupil Service is designed to be used in VR/AR setups, and the default calibration choreography here expects you to specify these positions. E.g.
import zmq, msgpack
# create a zmq REQ socket to talk to Pupil Service
ctx = zmq.Context()
pupil_remote = ctx.socket(zmq.REQ)
pupil_remote.connect('tcp://localhost:50020')
# convenience function
def send_recv_notification(n):
pupil_remote.send_string(f"notify.{n['subject']}", flags=zmq.SNDMORE)
pupil_remote.send(msgpack.dumps(n))
return pupil_remote.recv_string()
# set calibration method to hmd calibration
n = {
'subject':'calibration.should_start',
"translation_eye0": [34.75, 0.0, 0.0],
"translation_eye1": [-34.75, 0.0, 0.0],
}
print(send_recv_notification(n))
Hello I hope this is the right thread for this post (my apologies if not). I am interested in hopefully using Apriltags to track the position and distance of a moving object within the recording from the world camera of the pupil core (which I currently have) or even the Neon (which my lab may be purchasing in the near future) so that I can relate the object’s vertical, horizontal and depth position to the xyz gaze position.
To accurately calculate the position and distance of the AprilTag within the recording I have read that I will need to calibrate the eye tracker’s world camera to estimate the camera matrix and distortion coefficients. Given that the surface tracker plugin involves the detection of AprilTags I was wondering whether calibration code for estimating the world camera’s intrinsic parameters already exists and is available online?
I was also wondering whether there were features of the surface tracker plugin that I could utilize/modify for the purpose of determining the real world position and distance of an AprilTag within a recording?
Thanks a lot in advance.
Hey all. I have a Pupil Neon and want to stream the gaze video stream to a Mac process over USB (without the need for the android bridge). I explored UVC support and it looks like only the scene cam is UVC compatible. It looks like the android app is able to stream it over USB, is that something we can do as well directly?
You probably already know that the Real-time API is the recommended way to stream data from Neon to a PC, but I will just mention it here in case someone else comes across this message in the future.
With regards to accessing the eye cameras, the stream can be a little finicky to start with UVC, but it does work. It sometimes takes a few attempts. Here's an example:
import sys
import time
import uvc
import cv2
for device_info in uvc.device_list():
if device_info["name"] == "Neon Sensor Module v1":
uid = device_info["uid"]
break
else:
print("Camera not found")
sys.exit(1)
capture = None
for attempt in range(20):
try:
capture = uvc.Capture(uid)
time.sleep(1.0)
frame = capture.get_frame(timeout=1.0)
break
except:
if capture is not None:
capture.close()
print("Retrying...")
else:
print("Failed to open device")
sys.exit(1)
while True:
frame = capture.get_frame(timeout=1.0)
cv2.imshow("Eyes (press Q to quit)", frame.gray)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
capture.close()
On Mac you will need to run this as sudo
You found the right place!
For Pupil Core, default intrinsics for the scene camera are in the source code. These are generic though, and the measurements are designed to be a good fit among all Pupil Core headsets. For the most accurate measurements, you will want to calibrate the camera yourself as intrinsics will vary between cameras, even if they are the same brand/model. Pupil Capture includes a plugin to produce a calibration that can be used within Capture/Player.
For Neon, device-specific camera calibration data can be acquired through the Realtime API via Device.get_calibration.
For this specific use-case, have you considered the Head Pose Tracker plugin ? It assumes the AprilTag markers are fixed and calculates head pose over time. Since you want the tag pose relative to the head, you can just invert the head poses.
Thanks for this response. I will check out the default intrinsics and the plugin you mentioned for calibrating the camera myself (that's great to know I won't need to write my own script for this). Thanks for the info about the Neon as well.
I had not thought of the head pose tracker, no! But I will take a look to see if it will work for my purposes. Ultimately I want to be able to determine the position (including depth) of a moving target marked with an Apriltag in the same units/coordinate system as gaze position so I can directly compare the two and calculate pursuit gain and latency for smooth pursuit eye movements.
Hi devs, I would like to ask about the trigger integration with the 'e-prime' program to start and end recording.
I used the discord search function to see what other users had answered my question, but most of the links you provided were communication guidelines using python functions, and even on the 'pupil-labs/pupil-helpers' github page, there were only basic LSL / matlab / other python-related documents.
Currently, I have tested using the writestring or writebyte function of the Task event in E-prime, but it seems that the appropriate trigger signal does not work for the pupil capture program.
Based on my limited knowledge of TCP communication, I checked the guidelines, and it seems that this happens because the function using the 0MQ protocol does not work correctly unless the recv_string function is utilized as shown in the guide https://docs.pupil-labs.com/core/developer/network-api/. (It seems that the recall function is forced to write a separate script on the E-prime event setting).
Therefore, I would like to know if there is a guideline to start and end a record using only the Writestring and Writebyte features of the E-prime software with a simple GUI. (The last discussion on this was in 2020, so I would like to know any updates).
I ask this because I am not a software and telecommunications engineering major and ideally the pupilcore device should only function within e-prime in order to set up and train research nurses in a clinical setting where they will need to use this device.
If it is not possible, I think I will have to write a python-based exe program that works standalone and use it by creating a trigger delivery system that is delivered to e-prime -> python intermediary program -> pupil capture.
If you have any better ideas, please share. Thank you.
Hi @user-5e106e 👋 ! I do not have any experience with the e-prime program, although it looks similar to what PsychoPy or LSL offer, but seems to be connected to a hardware for sync, is that correct?
If you have more info about the protocol they use we could probably guide you.
Since you mentioned the helpers, have you seen this https://github.com/pupil-labs/pupil-helpers/blob/master/python/serial_bridge.py
First, thank you for your quick response. The software you mentioned is not python-based like PsychoPy and LSL, but it is a software that can provide a paradigm for measuring cognitive function that can be easily adapted into a GUI. However, it provides its own GUI and script-based functions, and it seems to be somewhat difficult to use these functions mixed with the python-based codes you provided.
e-prime basically supports the output of external signals from string to byte through various kinds of external synchronization settings, such as images. (As you asked, the trigger signal for sync is separately connected to hardware (in our case, EEG device Biosemi)).
In E-PRIME, it is possible to implement synchronization between data by using simple output-oriented operation such as serial communication or socket network communication (you just need to receive the trigger synchronization signal and store the trigger information in another data recorder), but in pupil equipment, it is based on one cycle of mutual information transmission, so it would be nice if the function that operates only with signals received from the outside (such as the recv_string mentioned) was supported.
In the case of the link you sent, it looks like the code supports building a serial communication port to send data from the pupil device to a separate device such as an Arduino. In our situation, it seems like we need to do the opposite: e-prime signal emission -> (change the signal from e-prime to use 0MQ protocol code by some connection method) -> Pupil capture program adds annotation or simply start/stop recording.
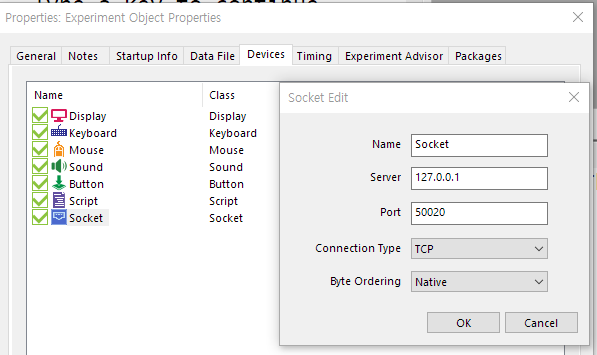
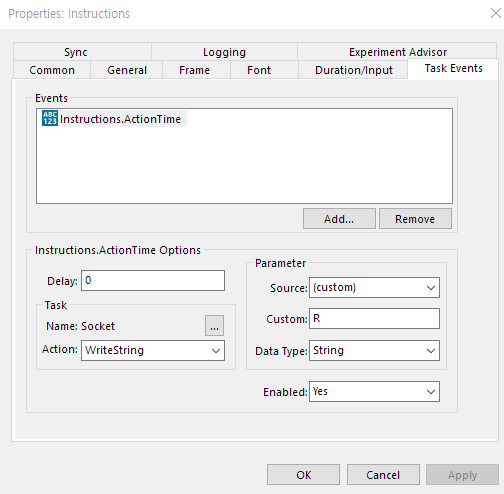
Additional reference webpage for e-prime task base event signal configuration (maybe it can be help you to understand...) https://support.pstnet.com/hc/en-us/articles/360020673193-DEVICE-How-To-Socket-Device-Communication-25288 https://support.pstnet.com/hc/en-us/articles/115015040608-E-STUDIO-Configuring-Task-Events-24789
Thanks for sharing this additional information. As you correctly noted, Pupil Core's network API employs ZeroMQ and, indeed, requires a handshake. Unfortunately, direct PUB-REQ communication from eprime seems not possible.
Thus, yes, you would need a bridge (in Python or another language with TCP socket and ZeroMQ support ) to receive signals from eprimeand forward them to Pupil Capture.
This setup might seem complex, and unless it's a strict requirement, exploring LSL (which features built-in integration) could be a more straightforward alternative.
If you opt to create a bridge, here's what you would need to implement:
Step 1: Establish a TCP Server in Python
Step 2: Forward Data to Pupil Capture Using ZeroMQ
pip install zmq msgpack==0.5.6Step 1B: Serial Communication via PySerial
If instead of TCP you want to use serial communication, install pyserial and establish a connection to the appropriate port for eprime.
This approach, although indirect 😅 , allows for the integration of eprime with Pupil Capture using existing tools and libraries.
I hope this helps
Thank you very much for your specific answer. It's going to take some time to actually implement this, but I'll give you a review when I do.
You're welcome! If I understand your project correctly, I do believe that inverting poses from the head pose tracker plugin will be the fastest and easiest way to achieve the results you're looking for. Either way, let us know what you end up doing 🙂
Amazing! Thanks very much! I will give it a try and let you know how it goes and/or if I have any follow up questions.
Hello, i'm currently doing my master thesis and im implementing the Pupil Core headset within an entire system of biosensors for monitoring in real time data from First Responder (nurses, firefighters etc...) My objective is to obtain data in real time with the Network Api to MongoDB - Docker. The thing is that im trying to run the Pupil Core in Visual Studio Code and when installing the requirements.txt appears an error. This error is related with the installation of uvc and the wheels. Im lost. Im on windows 11, Ive tried with virtual environment, installing wheel, installing cmake, -m build, the steps you provide in github in the uvc windows section but nothing. i can send you the error image. Could you help me im a bit desperate. Also, could you recommend me how do you think I should implement the system to upload it to Mongo and Docker, should I do it in visual studio, should I do it using the Capture app, I'm a bit lost with that too because I really don't know what to do after running it in python. How could I approach it? Very thank you in advance
Hi @user-4ab98e 👋 ! Is it okay if I first ask for some clarification? Then, I can be better positioned to help you.
Can you provide some more details about what the first responders will be doing and why you need the world camera video feed in real-time? Do you want to apply a computer vision algorithm to the video feed or you just want to look at the video feed?
In any event, you might not need to use pyuvc, as the Frame Publisher feature of the Network API already provides video streaming functionality.
Do you need to use MongoDB because the rest of your system uses that? I only say this because if we can avoid MongoDB integration, then that should make things easier. Is it that you want to save gaze/pupil/etc data into MongoDB and the video feed into an MP4 file?
Hi. I would like to know if anybody converted world_timestamp to relative timestamp, so i can get the same start from 0 for multiple records. Is there any ready to go solution?
Hi @user-612622 👋 ! Which eyetracker are you using?
Pupil invisible, but earlier i was using core
In the case of Pupil Invisible, you will find a field called "start_time" in the "info.json" file, in units of nanoseconds. You can subtract this from world and other timestamps, such as those for fixations, so that they are relative to 0 (i.e., start of recording).
In the case of Pupil Core, you can use the "start_time_synced_s" field of the "info.player.json" file and subtract that from the timestamps in files exported from Pupil Player, such as gaze_positions.csv. This will give you timestamps relative to 0 (recording start) in Pupil Time format in units of seconds. For an explanation, see our documentation.
Note that the first timestamp from the different datastreams will not necessarily occur at relative timestamp 0 as the different sensors need a moment to initialize before they start streaming data.
First of all thank you very much for your quick response.
Regarding to your questions:
The primary goal is to monitor the vital signs of first responders in real-time during emergency and disaster situations. We aim to measure and monitor their cognitive load while they perform their duties. In addition to controlled trials, we conduct various mental and physical tests to obtain data in different situations. The pupil cores will form part of a larger system that includes wristbands, chest bands, and other devices that collect data related to various biosignals, such as temperature, heart rate, and galvanic skin response. Regarding the use of the world camera video feed, we won't be utilizing it for our project. Instead, we're planning to work with CSV files to collect and analyze the necessary information.
I was unaware of the details of the second point. Although I have been using the headset for a few days, I am not yet fully familiar with its functionalities. My goal is what I said before, to export a CSV file to analyse the information provided by Pupil Core, including gaze speed, pupil diameter, fixations, blinks, and other parameters.
Yes, I'm new to python, does it show that much hahah? We are going to use MongoDB because the system architecture is already done in this software. My job is to implement the data provided by the pupil core real time glasses into the whole system. I want to generate csv files to analyse the signals in order to analyse the cognitive load of the first responders. Do you think I can achieve this knowing that I am new to python, or is it going to be very very difficult for me?
First, we hope to make things as easy for you as possible, so no worries and I am confident you will achieve a result Your research sounds very interesting!
May I ask if you already have multiple Pupil Core headsets or do you only have the one and you plan to purchase more? I ask because our latest product, Neon, makes data collection much simpler, especially in the context of emergency situations, as no calibration is required. You just put on the frames, hit "record", and get going. Also, Neon is smaller, unobtrusive, and mobile by design. With Pupil Core, you will need to calibrate/adjust it every time it is put on, as well as whenever it slips, which is certain to happen in an emergency scenario. You will also need to attach it to a SBC (it will not work with Raspberry Pi, but it will work with LattePanda), and put that somewhere on their body or in a backpack, and it will need a power source.
If you do not need to access camera video feeds in real-time, then you can safely skip the Frame Publisher feature and pyuvc.
If you want CSV files and you must use Pupil Core, then the easiest way is to make a recording with Pupil Capture and afterwards, you want to use Pupil Player to export the raw data to CSV. From your explanation, it sounds like all of the data analysis will be done post-hoc, so I think you do not need the Network API, but please correct me if wrong. When you hit record in Pupil Capture, all of the data that you want is already measured in real-time for you and saved to disk. Then, you can use MongoDB's methods to read in the CSV data for you. Again, Neon would simplify this process and you would still get out CSV files that could be imported into MongoDB.
I am a university student, and im working on this project with my university, the community of Madrid and Huawei. At the moment, with the funding we have, we have a Pupil Core unit and I think the first prototype will be with this device also because of the time we have. If everything goes well, we have planned implement this project. If all goes well, and we get the results we want, we will probably upgrade our devices on a large scale to supply the demand of many of our first responders here in spain. So i take the consideration of the neon device
I don’t want video in real time, what I want is the generation of the csv will be in real time, that’s why I thought I had to implement the api network.
Correct me if I'm wrong, but then I wouldn't need the api network because what you mean is that I just have to upload the CSV files generated on my disk once I record, right? My question is how can I do this? I've only been working on this project for a week and I don't really know how to approach it.
I think I may have misunderstood something. Do you want the process to be (1):
or do you want to do the following (2):
Once I know that, then I can provide clearer steps for getting your data.
In either case, I have not used MongoDB, so for info about how to load data into one of their databases, I would check out their documentation. I see that they at least have a tool for importing CSV files. If you are doing option #2, this tool seems like a good thing to try.
Hi Rob, what we are looking for is more the first option than the second. To give you an example, the way the other biosensors work is as follows:
-Real-Time data capturing -Storage -Uploaded to MongoDB.
For now, it's better to forget about MongoDB, so there's no confusion.
I'll update you on my progress, I've managed to install and run the program. I can communicate with Capture remotely and what I want is to read in real time the data I get when I export the file in Player. I mean, I want to skip the step of having to open the Player to consult the data. I want that while recording in Capture I can see the data such as blinks, speed gaze etc. etc. Do you think i can do this?
I really appreciate the effort and interest you are showing. Thank you very much
I have successfully implemented a code that intermediates between E-prime3.0's TCP Writebyte and Pupillaps using byte signals. Simply put, the easiest way to implement the integration was to use the python socket library to get information from E-prime to the python TCP server, and then use ZMQ to capture pupils.
If developers need to share code or E-prime settings for their implementation, I'd be happy to share. It would be great to see E-prime supported as a new feature if it can be added. Thank you.
Awesome! If you end up sharing the implementation somewhere, please let us know and we will include a link to it to https://github.com/pupil-labs/pupil-community
Hi @user-4ab98e , have you already had your free 30 min onboarding call? I feel like we can more efficiently answer your questions there and show you how the Pupil Core ecosystem works. There are a number of factors to account for with Pupil Core that will make it difficult to get good data with your first responders, and it is important that we clarify all of that first. Also, over the call, we can clarify what you plan to do with the data after you have saved it in MongoDB, as that is relevant for how to integrate Pupil Core into your current system. If your lab still has the order ID, could you send it to [email removed] Then, we can continue communication there.
Good morning Rob, I apologize for not responding to your message. Would you like to schedule a meeting at 16:00h? If that time is not convenient for you, we can arrange one for tomorrow morning.
Hola! @user-4ab98e , it might be better to not share order ID's over a public channel, please feel free to book your onboarding call at your earliest convenience
thank you
I think my team already complete the onboarding call, so we could continue the conversation here
Hi @user-4ab98e. If you want real-time visualization of the data obtained via the Network API, then you do not need to save it to a CSV file in real-time. You actually want to avoid doing that, as it is rather computationally expensive. When you receive the data from a Network API call, it will already be in a Python variable and you can give this variable directly to a plotting command, such as those from Matplotlib. Check our Pupil Tutorials Github repo for various examples of how to plot the data. Although those examples are for the files that you get from a Pupil Player Export, much of the plotting approach will be similar for real-time data. In your case, you will probably want to make use of Matplotlib's Animation utilities, as shown in this example for sensor data. Note that I cannot make any promises about the performance of this code and you may need to do a test or two, after adapting it to your situation.
Hi @user-cdcab0 I have been testing out the head pose tracker as you suggested and it is pretty impressive. I do have a few follow up questions though. 1) What are the units for head pose? Your website says "the unit of the coordinate system is defined as the physical length of the tracking markers." but I am not sure what that means. Where is the physical length of the tracking markers defined? 2) Could you please elaborate on what you mean exactly by "inverting poses from the head pose tracker" to get the horizonal, vertical and depth position of a moving AprilTag (when the head is stationary)? 3) This question probably links with the previous one. I am interested in knowing the horizontal, vertical and depth/distance position of the AprilTag relative to the observer, am I right in saying that these these metrics would correspond to translation_x, translation_y and translation_z respectively if there is only one AprilTag (that moves) and the head is stationary? 4) Is there an easy way to convert the head pose coordinates (or rather the coordinates for the position of the target being tracked (i.e. the AprilTag)) to be in the same units/scale as the gaze position xyz so that I can easily relate gaze position with target/AprilTag position (e.g. calculating and plotting pursuit gain and pursuit latency). Thanks very much!
100mm, then 1 unit of the head pose coordinates will be 100mm1m, which of us has moved? Let's say we're facing the same direction (e.g., you're looking at the back of my head) - when the distance between us increases by 1m, you might say that my z has changed by +1m in your frame of reference, but I would say that your z has changed by -1m in my frame of reference. You can see how these are directly related. The head pose tracker essentially calculates camera pose from the AprilTag marker's frame of reference, but the AprilTag marker's pose from the camera's frame of reference is directly related and calculable.Hi, I had a question about pupil labs cloud. When exporting the fixation data I noticed it provides timestamps to mark the beginning and end of fixations, but I am unsure how to map that onto specific time points in the video feed for analysis. Is it possible to include information like frame number when exporting the fixations data on from Pupil Cloud?
Hi @user-bba4b8 !
Regardless of whether you're working with Pupil Invisible or Neon, after downloading the timeseries data (CSV files) from the Cloud, you will find a world_timestamps.csv file. This file records the timestamp for each scene camera frame, formatted identically to that in the fixations.csv file.
You can check whether for that frame the timestamp is in between the start and end fixations.
Thank you! i was wondering if it was in another file. very helpful
Hi @user-cdcab0 Firstly, just wanted to say thanks for that. Your answer for 2) makes much more sense now. When I initially read your previous post I thought you might have meant taking the multiplicative inverse of head pose (not sure why, but I wasn't sure) but the additive inverse make much more sense. Following on from 4), when converted to mm (to match the units of 3d gaze point) and inverted the value of translation_x for head pose would be the horizonal position of the AprilTag in a given frame relative to the original position of the AprilTag in the first frame it was detect, correct? However, what is the reference point for the 3D gaze point value? E.g, a gaze_point_3d_x of - 60mm mean horizontal gaze is -60mm relative to what point? Is it possible to get to a point where I can directly compare AprilTag position to gaze position (eg. when the observer looks directly at the AprilTag (regardless of its real world location) gaze_point_3d_x,y,z would approximately equal translation_x,y,z)?
Secondly, I have continued to test out the head pose plugin but have run into a problem. In some of the videos I have been unable to calulate the markers 3D model because it says "failed: not enough markers were collected". I've only been using a single AprilTag as I'm only interested in tracking the position of a single moving target during smooth pursuit (head remains static). Since I want to use the plugin to track the movement of a single moving target marked with an AprilTag rather than the head, I'm not use how adding additional (presumably static) AprilTags to the scene would impact this.
Thanks for taking the time to respond to me by the way on this. The support on discord is one of the main reasons why my lab continues to buy from and recommend Pupil Labs.
when converted to mm (to match the units of 3d gaze point) and inverted the value of translation_x for head pose would be the horizonal position of the AprilTag in a given frame relative to the original position of the AprilTag in the first frame it was detect, correct?
That's mostly correct, but the position of the root AprilTag marker is always the origin. So it's not just relative to the original position of the AprilTag marker, but relative to every position of the marker since it is constant.
However, what is the reference point for the 3D gaze point value?
The center of the camera, same as OpenCV
"failed: not enough markers were collected"
The markers are all assumed to be in fixed positions, but this is technically relative to the root tag. So for you, the ideal configuration would be multiple markers on your moving target, and I think you'll find the most accurate results when the markers are not coplanar.
The support on discord is one of the main reasons why my lab continues to buy from and recommend Pupil Labs
Thanks for the feedback! One of my favorite parts of this job is hearing about all of the interesting and fun ways people make use of our offerings. Your project sounds like a good example of that, and I'd love to hear more about it!
That's mostly correct, but the position of the root AprilTag marker is always the origin. So it's not just relative to the original position of the AprilTag marker, but relative to every position of the marker since it is constant. Okay, so this answer left me a little confused to be honest. I don't get how this would work in my case if the root AprilTag is moving as it currently is in my recordings (since I'm currently only using one marker)??
The center of the camera, same as OpenCV This make sense for X and Y being the center of the video recording but I am less sure about where the origin of the Z value would be (i.e. at what distance from the camera center would Z = 0). Is the origin of the z axis the same plane as the camera in which case z can only be a positive value (since a -ve value would be behind the camera)?
The markers are all assumed to be in fixed positions, but this is technically relative to the root tag. So for you, the ideal configuration would be multiple markers on your moving target, and I think you'll find the most accurate results when the markers are not coplanar. Cool! The moving target will be a small flying drone so attaching multiple markers might be difficult but I will give it a try. To clarify, for this to work all of the markers would need to be attached to the moving target (including the root marker), i.e. there shouldn't be any static markers in the scene?
I don't get how this would work in my case if the root AprilTag is moving as it currently is in my recordings (since I'm currently only using one marker)??
I was referring to the original head poses (not your reverse-calculated ones). The head pose tracker assumes all tags are stationary, that the root tag is at the origin at all times, and that the camera is the only thing moving around. However, after you reverse-calculate, your camera will be at an assumed constant position at the origin and all of the tags will be moving around it
z can only be a positive value (since a -ve value would be behind the camera)
You have the right idea, but IIRC, z will always be negative
there shouldn't be any static markers in the scene
Yes, that's correct (for your case specifically). I believe the head pose tracker will actually throw out markers whose position can't be well-fit to the others, but ideally all of the markers would maintain a pose that remains constant relative to the root tag
The moving target will be a small flying drone
Neat! How close/far will the drone be from the observer? You may end up needing quite large markers depending on the distance
Ah... okay! Thanks for clarifying. That makes more sense now.
It will cover quite a large range from 40cm in front of the observer to 400cm, so ensuring the tags are always detectable will be (and so far is) a challenge. Is there a way to manually select a tag within a frame if the auto detection fails (in a similar way to how you can manually select the calibration marker during posthoc calibration)? I have done a test recording with the drone but the detection of the tags is pretty unstable even when they are clearly visible. Would it be possible to share a copy of the recording as any feedback I could please get on how to improve the tracking of the AprilTags would be amazing?
Hi PulipLabs Team! I want to use the glasses (specifically the outward camera + IMU data) to do some offline SLAM experiments. To do that I need the intrinsics+extrinsics of the camera/IMU sensor. I could not find them anywhere ... Do I need to do the sensor calibration myself or are you able to provide this information? Thanks!
Hi @user-b96a7d ! Could you kindly let us know which eye tracker are you using? Is it Neon? And whether you need this value post-hoc or in real-time? You may want to have a look at this example from our real-time API
Ah sorry yes! It is the neon module! But seems like the real time API is providing everything I need! Thanks!
If you want to read it from a recording you already made, note that this information is already stored in the calibration.bin file. See how you can read it an undistort the scene camera here
[email removed] ! Could you kindly let
There is no mechanism to manually select markers, unfortunately.
Please feel free to share a recording. I can probably guess that motion blur will be a significant challenge here, but let's have a look and see what might be done to improve the tracking for you
I figured that was the case but thought it worth asking nonetheless.
Amazing, thank you! I will shoot off an email now to [email removed]
Hey Hey,
I have a question (again) regarding pupil cloud. Is it possible to make only one face mapper per project? And if so why? I ask because in my case I have a dozen videos in one project and I need face detection on each video, but after doing it on one, the program does not allow me to do it on the others. Is it supposed to work that way?
Hi @user-06b8c5 👋 ! Have you received an error message? Just to clarify, you can apply any Enrichment to many recordings at once. For Face Mapper, you should only need to put the desired recordings in a Project and then when running that Enrichment, it will automatically include/run on all recordings in that Project. This is indicated by the "Recordings included" column in the Enrichments overview. Afterwards, if you want the videos, then you go to Visualizations and create a Video Render Visualization. Choose the completed Face Mapper Enrichment that you want to visualize and once started, it will run for all of the included recordings. After it is complete, click the download button in the Visualization display to get a ZIP file with all the face mapped videos. Please let me know if I misunderstood something.